-
クラスター分析
2021.03.16
-
クラスター分析とは
クラスターとは「集団」「房」を意味し、クラスター分析とは、異なる性質のものが混ざり合っているデータの中から、類似した性質のものを集めて集団(クラスター)を作り、対象を分かりやすく分類する手法です。『類は友を呼ぶ』 と言いますが、似通った対象どうしをグルーピングし、グループ(類)別の特徴や要因(友)を導きだすのに便利な分析です。
グルーピングする対象を何にするかで大きく2つに大別されます。変数クラスター分析とサンプルクラスター分析です。前者は回答のされ方が類似している質問項目(カテゴリー)をグルーピングする分析、後者は回答の仕方が類似している回答者をグルーピングする分析です。但し、それぞれの分析においてもいくつかの手法があり、異なる手法を用いれば、同じデータを用いても異なるグループ分けになることはよくあります。また、どんな質問項目をもとに分析するかによっても、生成されるグループは違います。ビジネスの実践で役立つ情報を導き出すには経験が必要な、繊細な分析と言えるでしょう。
2つの分類方法
類方法として、階層的方法と非階層的方法の2つがあります。
階層的方法
似ている対象の組み合わせを併合して順々にクラスター化していく手法で、最終的に樹形図(デンドログラム)が作成されます。類似性が近いものを徐々にグルーピングしていくため、併合過程が分かり易いのがメリットです。
非階層的方法
最初にクラスター化する数を決め、決めた数のグループにサンプルを分けていく手法です。似たものどうしが同じクラスターになるようにデータを分割し、最終的に個体レベルまで分割されます。サンプル数が多いデータを分析しやすいのがメリットです。
クラスター分析のメリットと用途
上述したとおり、クラスター分析はどんな項目をインプットデータに設定するか、さらにどの手法を用いるかによって結果が変わりやすいという難しさはあるものの、一定の手順にしたがって変数やサンプルをグルーピングできます。このメリットを活かした代表的な用途は、マーケットセグメンテーションです。どんな類似したグループがあり、それらはどんな理由で類似しているのか、さらに各グループの構成割合はどれ位かを客観的に導き出すのに役立ちます。
サンプルクラスター分析の課題
サンプルクラスター分析を活用する場合、大きく2つの課題があると弊社では考えています。下記の2つです。
①どんなサンプルクラスターか、ひと目で分かりにくい
もちろん、生成されたサンプルクラスターとその元となる質問項目とのクロス集計から特徴を割り出すことはできますが、ひと目では分かりにくいのが難点です。
②サンプルクラスターの有望度がメリハリあるとは限らない
サンプルをいくつかのグループに分け場合、目標と照らして、グループの有望度をメリハリ認識できれば都合がよいでしょう。しかし、通常のサンプルクラスター分析では、この点は考慮されていません。したがって、いくつかのグループができたものの、極端なケース、有望度がすべて同じということもあり得ます。効率性が求められるビジネスの実践では、生成されたグループの有望度にメリハリがなければ、そもそも分ける必要がないと言えるでしょう。
クラスター分析の事例
自主アンケート調査データをもとにしたクラスター分析事例を紹介します。
まずは、通常の方法によるサンプルクラスター分析結果と変数クラスター分析結果を示します。次に、上述したサンプルクラスター分析の課題を解決できるように考案した手法(ヒットプロセス分析)と、そのアウトプットを示します。
【調査概要】
- 調査の目的
フィットネスクラブにおける有望会員 (長期にわたり継続利用している会員) の特徴を把握し、会員の定着率アップに役立つ有力な手がかりを可視化することが目的です。 - 調査方法
インターネット調査 (自主調査) - 調査項目
・ 継続利用期間
・ 利用する際に重視する内容
・ 普段よく利用するサービスや施設
・ 属性 (性別、年齢) - 有効回収数 1000サンプル
- アンケート調査票

【クラスター分析の概要】
1.ローデータおよび仮説について
サンプルクラスター分析、変数クラスター分析を行うにあたり用いたローデータは、アンケート調査票のQ2ならびにQ3の各選択肢のデータです。クラスター分析にこれらのデータを用いた背景には、分析者の仮説があります。フィットネスクラブの利用者にはいくつかのパターンがあると考えられますが、それらのパターンを形成する要因は、「Q2.フィットネスクラブを利用するにあたり重視すること」や「Q3.普段よく利用しているサービスや施設」の選択肢に混ざり合っているだろう、という仮説です。
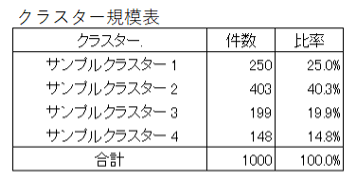
2.サンプルクラスター分析結果
サンプルクラスター分析と言っても、似たものどうしを束ねる際の計算方法により、さまざまな手法があります。当事例では、サンプル間の距離計算は原データのユークリッド距離、クラスター間の距離計算はウオ―ド法を用いて4つのグループ分けを実行しました。結果は下記のとおりです。
3.サンプルクラスターの特徴解明
サンプルクラスター分析の結果自体はとてもシンプルですが、これだけでは生成されたサンプルクラスターがどんなグループなのか、どのような理由で類似しているのかが不明です。そこで、これらを分かりやすくするための集計、分析が別途必要になります。それが、生成されたサンプルクラスターと元のQ2、Q3の選択肢とのクロス集計や、生成されたサンプルクラスターと元のQ2、Q3の選択肢による変数クラスター分析です。以下、それらの結果を示します。
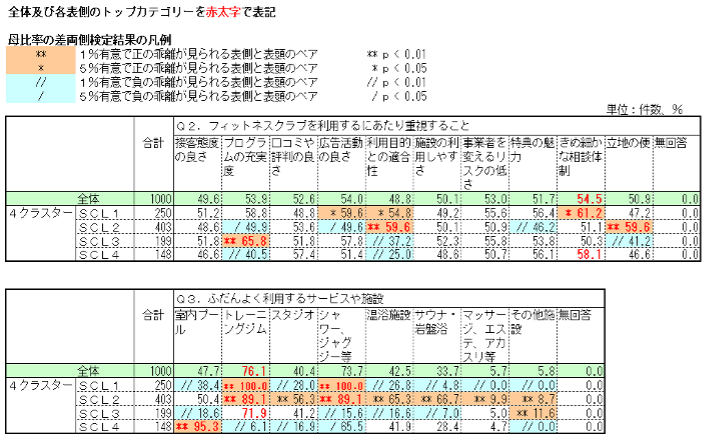
1.生成されたサンプルクラスター(SCL)と元のQ2、Q3の選択肢とクロス集計結果
表側の各サンプルクラスターと有意差が見られる表頭項目が、当該クラスターの形成に大きな影響を及ぼしている要因です。プラス影響の場合は「**」「*」、マイナス影響の場合は「//」「/」で表記しています。
これらの統計的検定結果をもとに各サンプルクラスターの特徴を見ると、SCL1は、よく利用するサービスや施設は「トレーニングジム」「シャワー・ジャグジー」、利用に際し重視することでは「利用目的との整合性」「きめ細かな相談体制」「広告活動の良さ」が求められています。“バリバリのトレーニング層”と言えるでしょう。SCL2は、よく利用するサービスや施設は「トレーニングジム」「スタジオ」「シャワー・ジャグジー」「温浴施設」「サウナ岩盤浴」「マッサージ、エステ、アカスル等」、利用に際し重視することでは「利用目的との整合性」「立地の便」が求められています。SCL1と共通する項目も見られますが、特徴はフィットネスクラブ本来の機能を期待している層というよりは、むしろ“スーパー銭湯的な利用層“である点です。SCL3は、「プログラムの充実」「その他の施設」の割合が有意に高い層です。SCL4は、圧倒的に「室内プール」の割合が高い ”室内プール層“です。
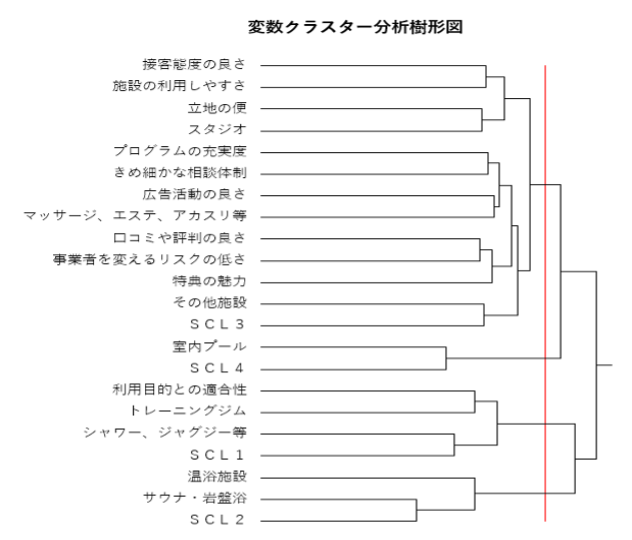
2.生成されたサンプルクラスター(SCL)と元のQ2、Q3の選択肢による変数クラスター分析結果
上記クロス集計結果でも各サンプルクラスターの特徴は分かりますが、俯瞰性をより高めた情報が得られるのが、変数クラスター分析樹形図です。共起性が強く、互いの相性がよい項目ほど、より近い位置で結ばれるスタイルをしています。①の結果とも符合することが見て取れるでしょう。
ここで当調査本来の目的に振り返った場合、決定的に不足している情報があります。それは、冒頭に示したフィットネスクラブにおける有望会員 (長期にわたり継続利用している会員) の特徴を把握し、会員の定着率アップに役立つ有力な手がかり情報です。
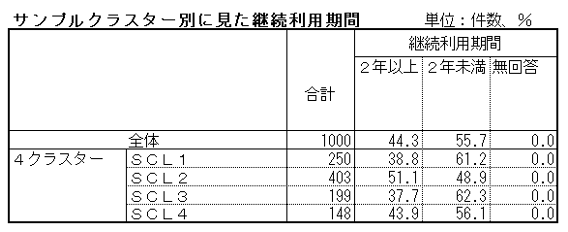
そこで、フィットネスクラブにおける有望会員を「2年以上継続利用している層」と定義し、これと生成された4つのサンプルクラスターとのクロス集計を行いました。
結果は次のとおりです。「2年以上」の割合は全体では44.3%、SCL2(51.1%)が最も高く、以下、SCL4(43.9%)、SCL1(38.8%)、SCL3(37.7%)と続きます。
サンプルクラスター2(SCL2)は規模の観点でも40.3%と、4クラスターの中では最大なので、狙い目としては問題ないでしょう。ただ、当該クラスターは、“スーパー銭湯的利用層” で代表されるクラスターなので、フィットネスクラブ本来の機能とは違った価値を求めている層であることは、とても興味深いです。
以上がアンケート調査分析でよく行われるサンプルクラスター分析、ならびに変数クラスター分析のアウトプットです。
【ヒットプロセス分析の概要】
最後に、通常のクラスター分析とは違うグルーピング手法をご紹介します。弊社が独自に開発した手法であり、「ヒットプロセス分析」 と名付けました。
当手法を開発した経緯は、目標に照らして通常のサンプルクラスター分析より、もっとメリハリある有望度を導き出せたら、さらにもっとシンプルにクラスターに該当するサンプルを特定できたら、ビジネスの実践で役立つと考えたからです。
ヒットプロセス分析の手順はきわめてシンプルです。目標を具体的に定義した上で、「目標達成層と未達成層」 を表側に設定し、これら2つの層を分ける要因候補を表頭に設定したクロス結果を活用します。当事例におけるクロス結果は次のとおりです。
フィットネスクラブにおける有望会員 (2年以上継続利用している会員) の主な特徴・要因として次のことが判りました。
・ 重視項目は、「立地の便の良さ」、「口コミや評判のよさ」
・ 普段よく利用するサービスや施設は次のとおりです。「シャワー、ジャグジー等」
「サウナ・岩盤浴」
「室内プール」
「スタジオ」
次に、「2年以上継続利用層」 の特徴・要因の中から3~4の要因を抽出し、それらを組み合わせることで、生成するグループの前提を具体的に定義します。
「立地の便」、「シャワー・ジャグジー等」、「口コミや評判の良さ」の3要因を組み合わせた場合の結果は下記のとおりです。
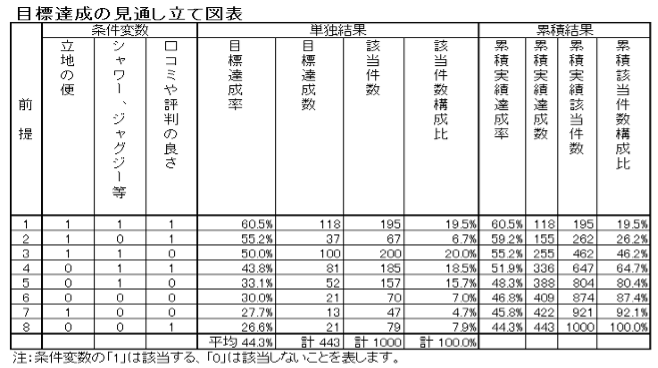
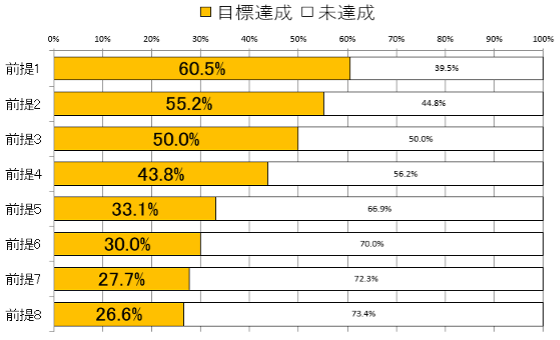
3要因を組み合わせた場合、2の3乗=8パターンの前提を生成できます。
これら8パターンの前提のうち、最も目標達成率が高いのは前提1の60.5%、反対に最も低いのは前提8の26.6%です。この比をとると、前提1の目標達成率÷前提8の目標達成率=60.5%÷26.6%=2.27です。
先に示した4サンプルクラスターの場合、最も目標達成率が高いのはSCL2の51.1%、反対に最も低いのはSCL3の37.7%です。同様にしてこの比をとると、SCL2の目標達成率÷SCL3の目標達成率=51.1%÷37.76%=1.36です。
前者の方が高い結果です。このように、目標に即してダイレクトにメリハリのあるグルーピングができることと、生成グループの基準が明快なので、マーケティング活動を行うにあたり、対象を特定しやすいメリットがあります。
弊社では通常のクラスター分析に加えて、ご要望があれば、当ヒットプロセス分析情報もご提供いたします。機会があればご検討のほど宜しくお願い申し上げます。
- 調査の目的